Advertisement
The way we store and retrieve information has changed dramatically in recent years. Traditional databases worked well when we were mostly handling numbers, text, and tables. But today, data is more complex. It’s images, videos, sound clips, and huge blocks of text that don’t fit neatly into rows and columns. That’s where vector databases come into play. They offer a smarter way to handle data that can’t be easily organized with old methods. If you’re curious about how it works and why it matters, you’re in the right place.
A vector database is specifically built to store data as vectors. A vector, literally speaking, is a set of numbers that describe a piece of data. Whether it's an image, a paragraph, or an audio recording, machine learning models can translate them into numerical forms. Once you have data as vectors, it becomes far simpler to compare, search, and identify relationships between different bits of information.
As an example, imagine searching for comparable images of a dog in an enormous repository. In a conventional database, you might need identical file names or metadata tags. However, in a vector database, you can search by the "meaning" of the image. The database will retrieve photos that resemble each other based on the content itself, not merely the tags.
This way of searching is called "similarity search," and it’s a major reason why vector databases are becoming so important, especially in fields like AI, recommendation systems, and natural language processing.
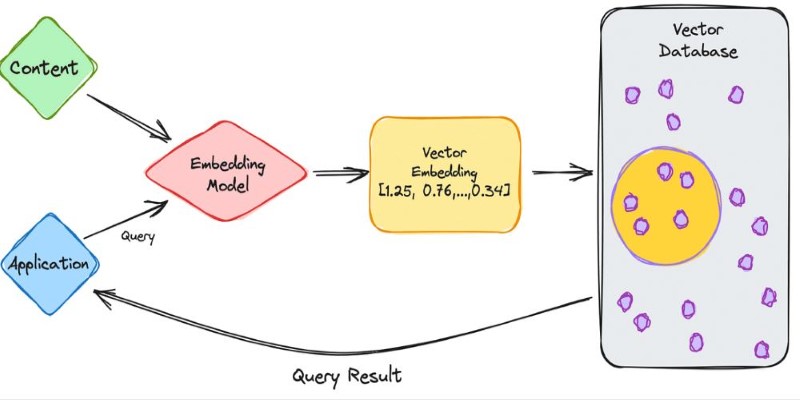
Before we get into why a vector database is useful, let’s quickly see what’s happening behind the scenes. When an AI model processes an item—like a song or a sentence—it turns it into a list of numbers, called an embedding. This list captures the key features of the item in a format a machine can understand.
So, instead of storing a "photo of a brown dog at the beach," the database stores a set of numbers that reflect everything about that image: the colors, shapes, and even the mood. These vectors usually live in spaces with hundreds or even thousands of dimensions. That sounds complicated, but it just means the database has a very detailed way of mapping out similarities.
When you search for something, the database looks for vectors that are "close" to your input vector based on their position in this high-dimensional space. It's like finding your friends in a giant park by seeing who's standing closest to you, not by shouting names into the air.
The process is incredibly fast, even with millions of items, thanks to smart mathematical techniques that narrow down the search without having to check every single item.
There’s a big reason why tech companies are excited about vector databases—they can handle the kind of data we’re creating today. Let's walk through some of the key reasons why they are becoming so popular:
With traditional databases, you had to know exactly what you were looking for. Type the wrong word, and you'll get no results. Vector databases change this. They allow you to find similar things even if you don't know the exact wording or details. Searching becomes more natural, like how people think and associate ideas.
For instance, if you search for "cozy winter sweater" in a vector database, it can pull up results that fit the feeling you're describing—even if those words don’t appear anywhere in the file names or tags. It's smart searching without all the fuss.
Structured data, like spreadsheets and forms, is neat and predictable. But most of the new data today is unstructured—things like emails, social media posts, audio files, or customer reviews. Vector databases can make sense of these jumbled sources by translating them into vectors, creating a uniform way to store and search complex information.
This ability is critical for industries that work with massive volumes of messy data, like healthcare, e-commerce, media, and finance.
One of the best parts about vector databases is how well they scale. Whether you have a few thousand vectors or billions, the database can still return search results quickly. Advanced techniques like approximate nearest neighbor (ANN) search allows the system to skip the heavy lifting and still find answers that are very close to what you're looking for.
So, whether it’s a small online shop recommending products or a tech giant organizing global images, the database keeps pace without slowing down.
If you're working with AI, chances are you're dealing with embeddings all the time. Models that understand language, recognize objects in images or predict user behavior are constantly producing vectors. Having a database built to store, search, and manage those vectors makes a huge difference in both speed and accuracy.
It’s like giving AI the right tools to finish the job faster and smarter. No wonder machine learning teams rely heavily on vector databases for their projects.

Several specialized tools have emerged to meet the growing need for vector storage. Some popular names include:
Pinecone: A fully managed vector database that handles the heavy lifting behind the scenes.
Milvus: An open-source option known for its flexibility and speed.
FAISS (Facebook AI Similarity Search): A library built by Meta to enable fast search on large datasets.
Weaviate: Combines vector search with structured metadata for hybrid queries.
Each one has its strengths, depending on your needs, but the common thread is the focus on vector-based search and storage.
Vector databases are changing how we handle modern data. By storing information as numerical vectors, they make it possible to search by meaning rather than exact match, organize messy, unstructured data, and scale to handle massive datasets without getting bogged down. They've quietly become a backbone for technologies we use every day, from smarter shopping experiences to better AI predictions. As our world continues to generate more complex data, vector databases are set to play an even bigger role.
Advertisement

Learn what stored procedures are in SQL, why they matter, and how to create one with easy examples. Save time, boost security, and simplify database tasks with stored procedures

Confused about whether to fine-tune your model or use Retrieval-Augmented Generation (RAG)? Learn how both methods work and which one suits your needs best

Explore how labeled data helps machines learn, recognize patterns, and make smarter decisions — from spotting cats in photos to detecting fraud. A beginner-friendly guide to the role of labels in machine learning
Working with rankings or ratings? Learn how ordinal data captures meaningful order without needing exact measurements, and why it matters in real decisions

Get a clear overview of Google's seven Gemini AI models—each built with a unique purpose, from coding assistance to fast response systems and visual data understanding

Wondering if there’s an easier way to add up numbers in Python? Learn how the sum() function makes coding faster, cleaner, and smarter

Looking for smarter AI that understands both text and images together? Discover how Meta’s Chameleon model could reshape the future of multimodal technology

Think data science is just coding? See how math shapes predictions, decisions, and the models that power everything from apps to research labs

Looking for a laptop that works smarter, not harder? See how Copilot+ PCs combine AI and powerful hardware to make daily tasks faster, easier, and less stressful

Wondering why your data feels slow and unreliable? Learn how to design ETL processes that keep your business running faster, smoother, and smarter

Confused about machine learning and neural networks? Learn the real difference in simple words — and discover when to use each one for your projects

Looking for a better way to code, research, and write in Jupyter? Find out how JupyterAI turns notebooks into powerful, intuitive workspaces you’ll actually enjoy using