Advertisement
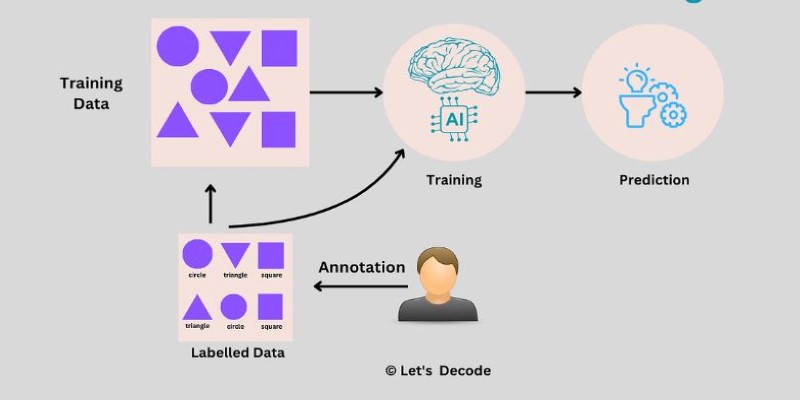
When you hear people talk about machine learning or artificial intelligence, one phrase that often pops up is “labeled data.” It sounds pretty technical at first, but the idea behind it is surprisingly easy to understand. Labeled data is simply information that has been tagged with one or more meaningful labels, making it useful for teaching a computer how to recognize patterns, make decisions, or predict outcomes. Think of it like flashcards for machines — instead of a word and its definition, each piece of data comes with a tag that explains what it is. And trust me, without labeled data, a lot of the tech we rely on every day just wouldn’t work.
Machine learning models are like students — they learn by example. But without examples that are clearly explained, they would have no clue what to learn from. That’s where labeled data steps in. Each label helps the model know exactly what it’s looking at, whether that’s a picture of a cat, a recording of someone saying “hello,” or a review saying a product was great.
Take image recognition as an example. If you show a model thousands of unlabeled pictures of cats and dogs, it won’t understand what makes a cat different from a dog. But if you label the cat images as “cat” and the dog images as “dog,” the model can start spotting the differences — like fur patterns, ear shapes, or the way the tail curves.
And it's not just for pictures. Labeled data is used for everything from understanding speech, translating languages, and spotting fraud in banking to recommending the next show you might want to watch. Every success story you hear about artificial intelligence has labeled data quietly working in the background.
Not all labeled data look the same, and that's because different tasks call for different types of labels. Here's a simple look at a few common types:
This is one of the easiest ones to spot. Each item gets sorted into a category. For instance, an email could be labeled "spam" or "not spam." A photo could be labeled as a "cat," "dog," or "rabbit." Models trained with classification labels learn to place new items into the right categories.
Instead of labeling an entire image, object detection labels mark exactly where an object is located inside the image. A picture could have several boxes drawn around different objects with tags like "car," "person," or "stop sign." This kind of labeling helps models know not just what something is but where it is.
Ever wonder how websites figure out if a review is positive or negative? It’s because of sentiment labels. Text is labeled based on the feeling it expresses — happy, angry, frustrated, satisfied — and models learn to spot emotional tones all on their own.
Sequential labels have become really important for things like language. In this case, every part of the data — like every word in a sentence — gets its label. It's how models can be trained to understand grammar, names of people, dates, and other key parts hidden inside blocks of text.
Creating labeled data sounds simple, but it can actually take a lot of time and effort. Humans are usually the ones doing the hard work — reading through content, looking at images, listening to recordings, and tagging everything carefully.
Sometimes, companies hire specialists who are trained for it. Other times, everyday users help out without even realizing it. For example, when you confirm that a CAPTCHA image shows a bus or a traffic light, you're helping build labeled datasets used to train models.
There are a few different ways labeling gets done:
Manual Labeling: People do it by hand. It's slow but very accurate when done right.
Programmatic Labeling: Automatic systems make guesses based on certain rules or keywords. It’s much faster but can be less reliable if not double-checked.
Crowdsourced Labeling: Platforms like Amazon Mechanical Turk let large groups of people label data for small payments. This helps scale up the amount of labeled data quickly.

Synthetic Labeling: Sometimes, labels are created artificially. For example, in a driving simulator, cars and pedestrians can be labeled automatically because the simulator already "knows" where everything is.
No matter which method is used, the goal is always the same: clean, consistent labels that help models learn the right things.
You can have millions of examples, but if the labels are wrong or sloppy, your model will end up confused. It’s a bit like learning math from a teacher who keeps making mistakes on the blackboard — you won't get very far.
Bad labeling can cause models to make silly errors. A self-driving car could mistake a tree for a stop sign. A medical diagnosis tool could miss spotting early signs of disease. These are mistakes no one wants.
This is why companies often invest a lot in quality control. They double-check labels, run test models, and clean up their datasets before trusting a model to learn from them. In some industries, like healthcare or finance, getting labeling right is considered non-negotiable.
Labeled data might not seem exciting at first glance, but it’s the backbone of almost everything smart computers can do. Without it, a machine would just sit there, staring blankly at a pile of information with no clue what it means. Thanks to labeled data, we have models that can spot a cancer cell, translate between languages, predict weather patterns, and even help farmers grow better crops. Next time you use voice recognition, shop online, or scroll through personalized suggestions, you'll know that labeled data made it all possible.
Advertisement

Explore how labeled data helps machines learn, recognize patterns, and make smarter decisions — from spotting cats in photos to detecting fraud. A beginner-friendly guide to the role of labels in machine learning

Wondering how everything from friendships to cities are connected? Learn how network analysis reveals hidden patterns and makes complex systems easier to understand

Ever wonder how data models spot patterns? Learn how similarity and dissimilarity measures help compare objects, group data, and drive smarter decisions

Want to learn how machine learning models are built, deployed, and maintained the right way? These 8 free Google courses on MLOps go beyond theory and show you what it takes to work with real systems

Understand the principles of Greedy Best-First Search (GBFS), see a clean Python implementation, and learn when this fast but risky algorithm is the right choice for your project

Looking for a better way to code, research, and write in Jupyter? Find out how JupyterAI turns notebooks into powerful, intuitive workspaces you’ll actually enjoy using

Working with rankings or ratings? Learn how ordinal data captures meaningful order without needing exact measurements, and why it matters in real decisions

Get a clear overview of Google's seven Gemini AI models—each built with a unique purpose, from coding assistance to fast response systems and visual data understanding

Confused about machine learning and neural networks? Learn the real difference in simple words — and discover when to use each one for your projects

Looking for a laptop that works smarter, not harder? See how Copilot+ PCs combine AI and powerful hardware to make daily tasks faster, easier, and less stressful

Wondering why your data feels slow and unreliable? Learn how to design ETL processes that keep your business running faster, smoother, and smarter

Apple unveiled major AI features at WWDC 24, from smarter Siri and Apple Intelligence to Genmoji and ChatGPT integration. Here's every AI update coming to your Apple devices