Advertisement
Choosing between fine-tuning and retrieval-augmented generation (RAG) can feel like picking between two solid options for improving your AI model. Each one has its benefits, but the best choice often depends on what you need and the type of experience you're looking for. Before you decide, it helps to know how each method actually works and where it shines. So, let’s explore the difference in a clear and relatable way — no jargon overload here! Whether you need a model that adapts over time or one that’s finely tuned to your exact requirements, both approaches offer distinct advantages. Understanding their unique strengths will help you make the right decision for your project.
Fine-tuning then trains an already existing model by providing it with more focused examples. Consider it as you're teaching an intelligent student who already has knowledge of the basics but requires some additional guidance on a specific subject. You feed it new data, and it tunes its inner settings to execute better for your purposes.
The magic with fine-tuning is that once the model learns from your examples, it doesn’t need to ask anyone else for help. It carries everything it needs right inside. This can be great if you're after faster answers or need the model to behave in a super-specific way without depending on outside information.
The downside? Fine-tuning can be time-consuming, and it often needs more computing power. You also have to be extra careful when feeding it examples because if the data is off, the model can learn the wrong things. Plus, once fine-tuned, updating the model means doing the whole process again, which isn’t always fun.

RAG (Retrieval-Augmented Generation) takes a different path. Instead of cramming all the knowledge inside the model, it lets the model fetch information from a trusted source when needed. Picture someone answering questions by quickly skimming a well-organized library. They don’t try to memorize every book — they just know where to look.
With RAG, the model pulls in the most relevant documents from an external database or knowledge set in real time. This is awesome if you're dealing with information that changes often or if you can't afford to retrain your model every few weeks.
Because RAG separates the "thinking" from the "knowing," it tends to stay lighter and quicker to adjust. Update the documents, and boom — the model can give fresh answers without needing a whole new training session. It’s a flexible way to keep your information current without much heavy lifting.
However, RAG isn't flawless. It depends heavily on how good the retrieval part is. If it pulls the wrong document, the answer won't be great, no matter how skilled the model is at generating text. You also have to manage the knowledge base properly — outdated or messy information can make things worse.
If you need a model to act in a very specific way, fine-tuning wins. Let's say you're building a legal advisor AI for one particular country. Training it on thousands of cases and laws from that country means the model becomes laser-focused. It understands the context better and can respond naturally without having to search for information every time.
Fine-tuning is also helpful when you're working offline. If your environment doesn't allow external queries — like confidential medical records or sensitive financial data — keeping everything inside the model avoids unnecessary exposure.
Another thing to consider is speed. Since a fine-tuned model doesn't have to search for answers, it usually responds faster. So, if you're building something where split-second answers matter, like a customer service chatbot, fine-tuning can give you that little extra push.
That said, fine-tuning locks your model into whatever knowledge it learned. If your field changes — like tech, medicine, or finance often does — you’ll have to retrain the model from scratch to keep it sharp.
RAG becomes your best friend when information is dynamic. Say you're creating a tool for cybersecurity updates. Things in that space shift daily. Instead of retraining a whole model every time new threats appear, you must update your knowledge database, and RAG handles the rest.
RAG is also the smarter move if your information is too large or detailed to stuff into a single model. For example, building a reference tool for global historical archives would be better handled by fetching only what’s needed rather than trying to jam decades of records into the model's memory.
Cost is another thing in RAG’s favor. Fine-tuning big models can be pricey — very pricey. But with RAG, you can use smaller models and still get high-quality results by linking them to excellent databases. It’s a smarter use of resources when budgets and timelines are tight.
One thing to keep in mind: RAG needs a well-maintained, organized knowledge set. If your documents are a mess or if your retrieval system isn't tuned properly, the whole setup can crumble quickly.
Fine-tuning and RAG both have strong cases. Fine-tuning is your go-to when you need a sharp, fast, and super-specialized model that stays consistent over time. RAG is the better pick when you need flexibility, fresher information, or when you’re dealing with massive or fast-changing data. Choosing between them really boils down to what you want from your AI: a steady expert who memorizes everything you teach or a quick learner who knows how to find the right answers at the right time.
Whichever road you choose, the key is knowing your needs first — and then setting up your model to match that vision. No one-size-fits-all answer here, but that’s part of what makes building AI tools exciting. Hope you find this info worth reading. Stay tuned for more informative guides.
Advertisement

Working with rankings or ratings? Learn how ordinal data captures meaningful order without needing exact measurements, and why it matters in real decisions

Ever wonder how data models spot patterns? Learn how similarity and dissimilarity measures help compare objects, group data, and drive smarter decisions

Curious about Llama 3 vs. GPT-4? This simple guide compares their features, performance, and real-life uses so you can see which chatbot fits you best

Looking for smarter AI that understands both text and images together? Discover how Meta’s Chameleon model could reshape the future of multimodal technology

Wondering who wins in coding—ChatGPT or Gemini? This 2025 guide compares both AI chatbots to help you choose the better coding assistant
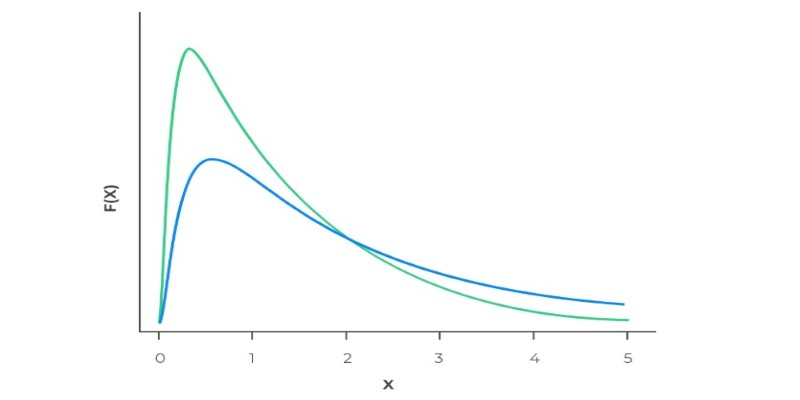
Ever wonder why real-world data often has long tails? Learn how the log-normal distribution helps explain growth, income differences, stock prices, and more
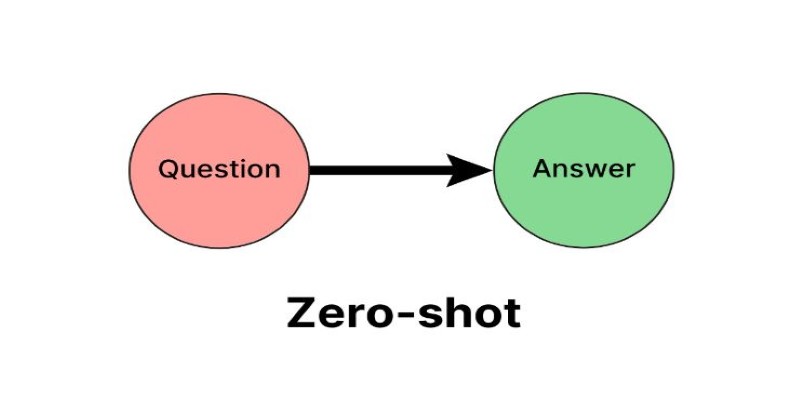
Learn what Zero Shot Prompting is, how it works, where it shines, and how you can get the best results with simple instructions for AI

From training smarter AI to protecting privacy, synthetic data is fueling breakthroughs across industries. Find out what it is, why it matters, and where it's making the biggest impact right now

Tired of missed calls and endless voicemails? Learn how Synthflow AI automates business calls with real, human-like conversations that keep customers happy and boost efficiency

Learn how to build an AI app that interacts with massive SQL databases. Discover essential steps, from picking tools to training the AI, to improve your app's speed and accuracy

Wondering if there’s an easier way to add up numbers in Python? Learn how the sum() function makes coding faster, cleaner, and smarter

Looking for a better way to code, research, and write in Jupyter? Find out how JupyterAI turns notebooks into powerful, intuitive workspaces you’ll actually enjoy using